Investigating Enron’s email corpus: The trail of Tim Belden
In fraud and white collar crimes, forensic investigators often have to go through massive amounts of complex connected data to gather proofs and evidence for their cases. In the recent years, the development of graph databases and data visualization tools have made it much easier to quickly find information that would have taken days to find by other means. Let’s see how Linkurious can help investigate a real life email network dataset to establish responsibilities or proofs of guilt. We’ll use real emails coming from Enron, one of the biggest financial scandal in US history.
Investigating Enron’s emails
In October 2001, the U.S. Securities and Exchange Commission (SEC) began investigating what would rapidly become known worldwide as the Enron scandal. The energy company had been using accounting loopholes and offshore platforms to conceal billions of dollar of debt in its financial reports for years. It was also found to have manipulated the Californian and Canadian energy market to push prices up artificially to increase its profit. The scandal eventually led to Enron’s bankruptcy making it the biggest company reorganization in American history at the time. Many executives were indicted and trialed.
During its investigation, the Federal Energy Regulatory Commission (FERC) made the controversial decision to publish online all of the company’s emails for transparency, historical and academic research purposes. The “Enron email corpus”, as it is now widely known, constitutes the largest public domain database of real world company e-mails in the world and has been used in a very large range of studies and research projects worldwide.
Importing the email corpus into Neo4j
To start exploring the corpus, we needed to import it into a Neo4J graph database. In order to do so, we relied heavily on Arne Hendrik Schulz’s work and his MySQL 4 dumps of the dataset that we turned into CSV files. The result is a graph with 328,209 nodes and 2,317,231 relationships. You can learn more about how to import large datasets into Neo4j here.
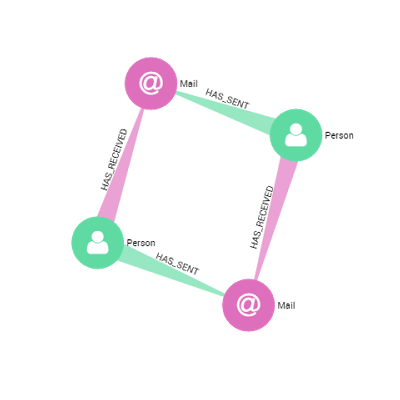
Our graph model is pretty simple, we have 2 types of nodes: persons and emails. Persons are linked to emails by “HAS_RECEIVED” and “HAS_SENT” relationships. We could use Linkurious to explore the email contents themselves, but for this article, our interest is more to explore the network of key executives in the scandal to see if we can find interesting information that could be useful for investigators.
Investigating Tim Belden’s network
Tim Belden, the head of trading at Enron, was one of the first executives to be prosecuted and to admit wrongdoings at Enron. He pled guilty on charges of conspiracy to commit wire fraud as part of a plea bargain and agreed to cooperate with the authorities to help convict many top Enron executives. He’ll be the starting point of our fictive investigation. Let’s see if we can find relevant information just by analysing his email activity.
The first problem we have to deal with here is that a lot of emails he sent and received were directed to many recipients. The ones that are really interesting to us as investigators are his personal emails. An easy and quick way to isolate them is to expand only the least connected nodes in his sent and received emails. That way, we find the interlocutors with whom he had direct one-to-one contact. This method is really effective if we do not need a 100% precision level to explore the data.
A quick look at the graph shows that he used his email address primarily to send emails to the Enron’s World Trade center Office: ‘center.dl-portland@enron.com’. But he did send a few emails to individuals inside the company as well.
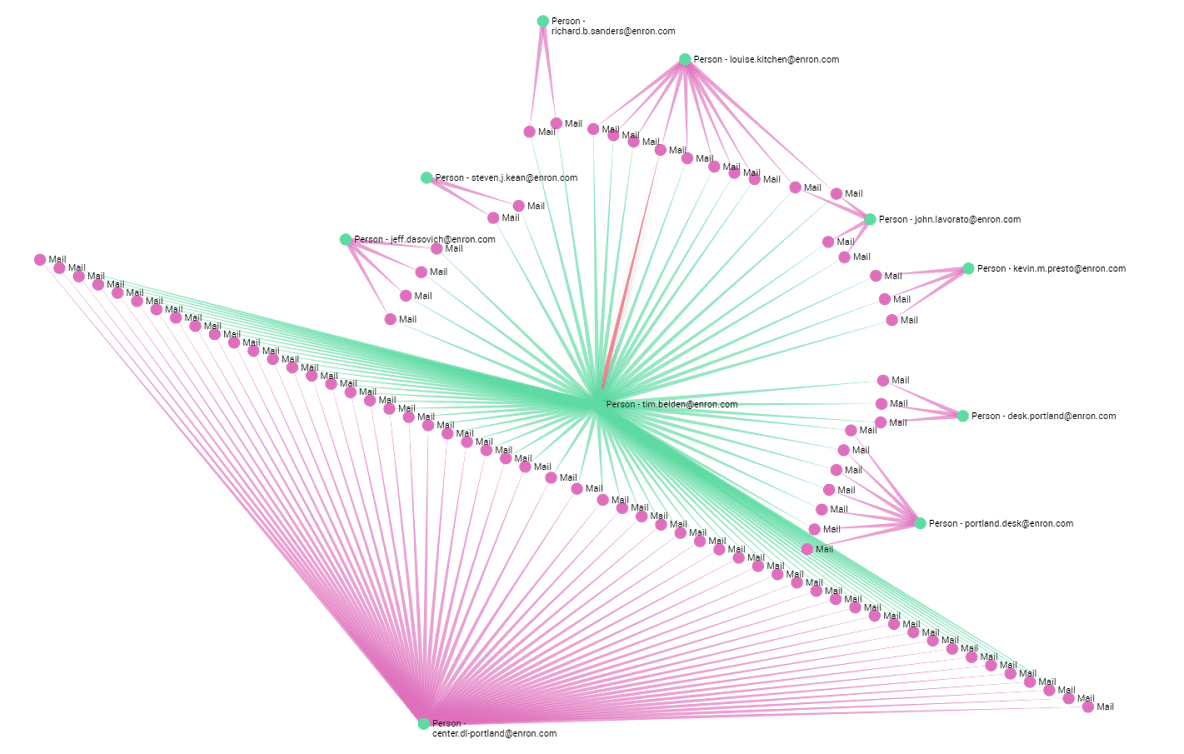
Now, if we get rid of all the emails sent to the WTC office and add the 200 least connected emails he received we get a map of all his interactions inside Enron. After cleaning the uninteresting emails we see that his primary interlocutors inside the company were: John Lavoreto, Jeff Dasovich, Kevin M. Presto, Philip K. Ellen, Louise Kitchen and Kate Symes, all top executives at Enron. Dasovich was Enron’s governmental affairs executive, Presto was Vice President, Lavoreto and Kitchen were senior traders, and Ellen and Symes were both traders as well.

Assessing Belden’s relationships
Now let’s play the part of a forensic investigator who wants to assess Belden’s Relationships inside the company. Lavoreto appears to be by far the individual with whom he had the most interactions even though he only sent a few emails to him. With such information, an investigator could have decided to investigate their relationship furthermore. Doing so he could have discovered a conversation between the two proving that they both knew Enron was actively manipulating the Canadian energy market in August 2000. The scam operation was called project Stanley. As the FERC most probably lacked the tools to explore the dataset efficiently, this story only came out in 2005. If they had had a tool like Linkurious they would have been able to spot significative relationships more easily and would have known which emails to drill into.

Now, we can also investigate whether the people in Belden’s first circle knew each other. An easy and effective way to do this is to use the “find the shortest path” feature of Linkurious. For example, let’s check if Lavoreto and Dasovich interacted together directly. Instantly we see that they never exchanged any private emails but only received the same chain emails with many recipients.
On the other hand, Lavoreto and Presto did have many private email interactions. It could be interesting to investigate their relationship as well since they are both connected to Belden.
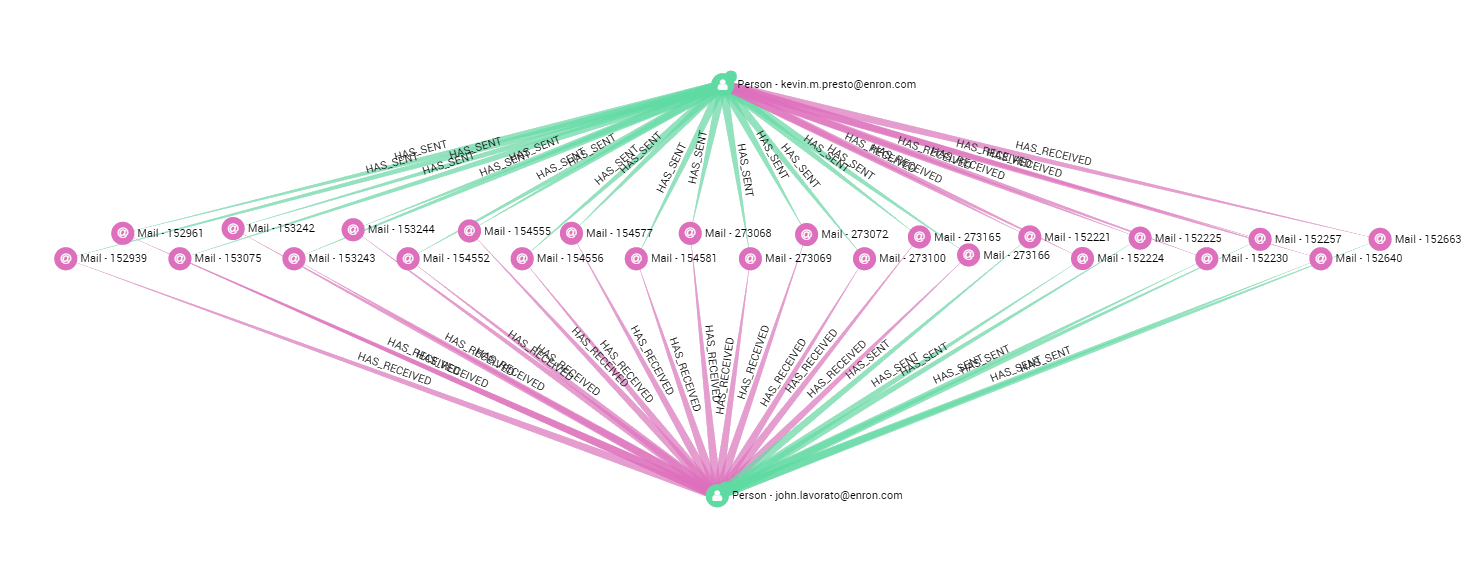
A quick search on google tells us that the FERC established in 2002 that “Presto’s role paralleled that of Tim Belden” and that he was also involved in project Stanley too. Using the dataset we can establish that Balden, Lavoreto and Presto were part of the same circle inside and communicated together.
Querying the dataset
Now let’s see how we can return nodes that fit more complex patterns and criteria in the dataset. Cypher queries, Neo4j’s query language, can be entered directly in Linkurious. For example, this request returns all the nodes ending by “@enron.com” that never sent any emails. This could be a potentially useful query if the investigators suspect some emails were deleted from the dataset and they wish to check which email addresses were altered.
// Cypher request:
match (n)–()
with n,count(*) as rel_cnt
where 1<rel_cnt<=2
match (n:Mail)–(:Person{email:”tim.belden@enron.com”})
return n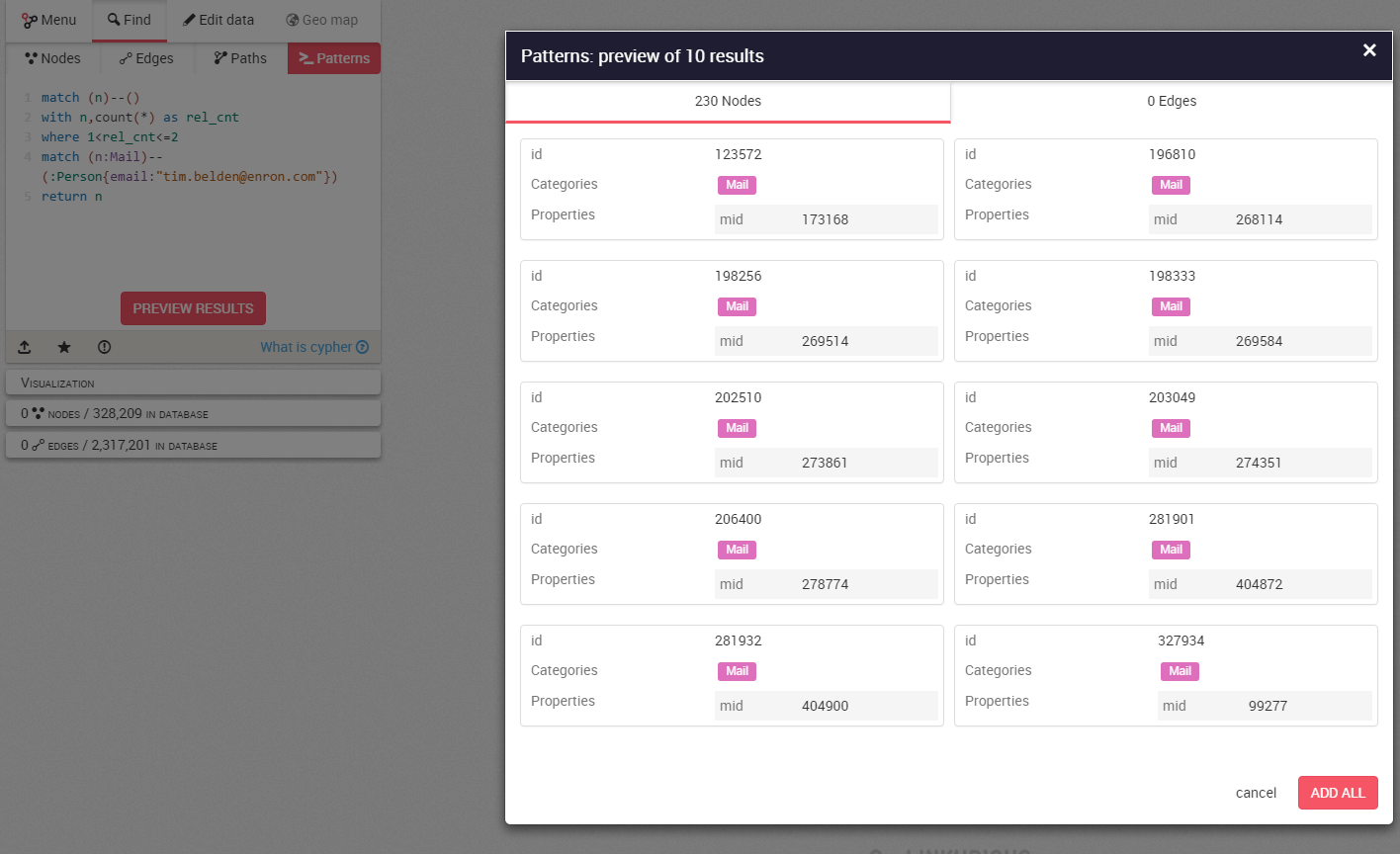
The result is nearly exactly the same as what we had earlier when we expanded Belden’s least connected emails, except this time we’re sure not to have missed any nodes that fit the criteria we have set. It is just a more rigorous and precise way of obtaining a map of his interlocutors, but at least we’re sure not to miss a single email!
If anything this exercise demonstrates the power of graph visualisation when investigating or auditing a network. Without even having read the emails, we managed to establish who belonged in Belden’s first circle inside Enron and established that some people in his network knew each other as well. It turned out that Belden, Lavorato and Presto indeed knew about project Stanley and were all potentially involved in it. Linkurious is the perfect tool to investigate social networks in detail, find key people and communities, establish responsibilities and relationships. Linkurious can be used to conduct large-scale audits or investigation inside large organisations of any kind.
Want to explore and understand your graph data? Simply watch our demo of Linkurious Enterprise!
A spotlight on graph technology directly in your inbox.